Parameter Estimation: Approximate Bayesian Computation#
Here we demonstrate how PyGOM uses Approximate Bayesian Computation (ABC) to estimate posterior distributions for parameters given a candidate model and some data. As an example, we use synthetic data produced by PyGOM’s solve_stochast function, the result of a stochastic epidemic simulation of an SEIR model with parameters:
\(\beta=0.35,\quad \alpha=0.5,\quad \gamma=0.25,\quad n_{\text{pop}}=10^4,\quad I(t=0)=5\)
Loading in the data file:
import numpy as np
out = np.loadtxt('seir_epi_data.txt')
t=out[:,0]
sol_i_r=out[:,1:3]
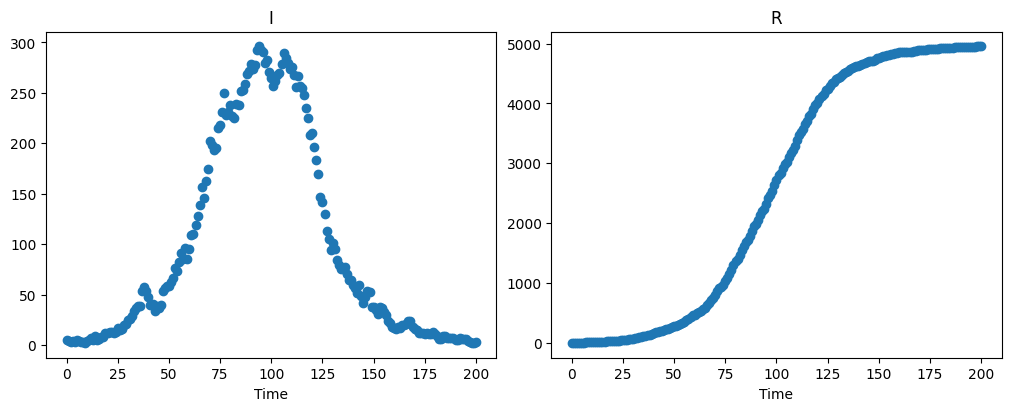
We inspect the time series of the daily infected and removed populations:
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 4]
f, axarr = plt.subplots(1,2, layout='constrained')
axarr[0].scatter(t, sol_i_r[:,0])
axarr[1].scatter(t, sol_i_r[:,1])
axarr[0].set_title('I')
axarr[1].set_title('R')
axarr[0].set_xlabel('Time')
axarr[1].set_xlabel('Time');
Note
We typically do not have access to information regarding the total infected population. More commonly reported is the number of new cases in a given time period (or infection times). Furthermore, we are unlikely to know the removed population, unless, for example, the disease results in death with high probability. Nevertheless, the purpose of this chapter is to demonstrate model fitting given a data set and so these departures from reality do not undermine the key messages.
In the next sections, we are going to use PyGOM to obtain estimates for unknown values \(\beta\), \(\alpha\) and \(\gamma\) (assuming that the total population, \(N\), and initial number of infecteds, \(I(t=0)\), are known).
Note
Again, it is rather unrealistic to know \(I(t=0)\) or indeed \(N\), but we proceed in this way for the sake of simplicity in our example.
Fitting an SEIR model (with Infected and Removed known)#
To obtain parameter estimates from data, we must provide a candidate model and specify the unknown parameters which we are interested in. Information regarding the candidate model is contained in abc.create_loss(), which requires:
A
SimulateOdeobject which describes the system of ODEs.The loss function, which describes how we assume observations are distributed about the mean value predicted by the
SimulateOdeobject.abc.Parameterwhich indicates which parameters we are interested in and their prior distributions.The data to which we are fitting the parameters.
We start by specifying the ODE system. In this first example, we are going to assume (correctly) that the underlying process is an SEIR model. We need to let the model know the value of \(N\), however, a feature of PyGOM is that we must pass values for all parameters. This usually acts to ensure that we do not under-specify the set of parameters when running simulations, however, in this case it requires us to overspecify what we actually know. Thus, even though the other parameters (\(\beta\), \(\alpha\) and \(\gamma\)) are unknown, the model expects some values and so for now we can just pass some initial guess (in this case the half way points of our prior distributions defined below), which will be overrode later when we specify ABC parameters.
# Set up pygom object from common models
from pygom import common_models
n_pop=1e4
paramEval=[('beta', 0.5), ('alpha', 1), ('gamma', 0.5), ('N', n_pop)]
ode_SEIR = common_models.SEIR(param=paramEval)
The Parameter class is used to specify the parameters we wish to infer and their prior probability distributions.
We can choose from any of the distributions included in PyGOM, here taking uniform distributions.
from pygom import approximate_bayesian_computation as abc
parameters = [abc.Parameter('beta', 'unif', 0, 1, logscale=False),
abc.Parameter('alpha', 'unif', 0, 2, logscale=False),
abc.Parameter('gamma', 'unif', 0, 1, logscale=False)]
Finally, we must specify how observations are produced from the underlying model.
If we assume that each data point is the result of a random draw from a Poisson distribution with mean equal to the SEIR model output at that timepoint, we can use the option PoissonLoss as our loss function when calling create_loss below.
Now we combine everything together, including the initial conditions which we are assuming to be known.
i0=5
x0=[n_pop-i0, 0, i0, 0]
from pygom import PoissonLoss
objSEIR = abc.create_loss("PoissonLoss", # Loss function
parameters, # Unknown parameters and prior distributions
ode_SEIR, # Model
x0, t[0], # Initial conditions and timepoints
t[1:], sol_i_r[1:,:], # Data timepoints and I, R values
['I', 'R']) # Names of compartments in data
abcSEIR = abc.ABC(objSEIR, parameters)
A sequential Monte Carlo method (ABC-SMC) is used for parameter inference. This approach considers a series of generations, with each generation using a smaller threshold than the previous. The first generation is equivalent to the standard ABC algorithm, in the sense that parameters are sampled from prior distributions. In subsequent generations, candidate parameters are proposed by perturbing weighted samples from the previous generation. Here, we use a multivariate normal distribution with optimal local covariance matrix to perform the perturbation.
The ABC-SMC method requires a couple of additional arguments to get_posterior_sample:
G - the number of generations.
q - a quantile (0 < q < 1). Whilst it is possible to specify a list of tolerances to use in each generation, it is difficult to know what these should be. When specifying q, the tolerance for the current generation is set to the q-th quantile of the distances from the previous generation. Larger values of q will result in smaller reductions in thresholds but a higher acceptance rate.
We run for 6 generations on our data
np.random.seed(1)
abcSEIR.get_posterior_sample(N=250, tol=np.inf, G=6, q=0.25, progress=True)
Generation 1
tolerance = inf
acceptance rate = 74.40%
Generation 2
tolerance = 364073.42362
acceptance rate = 17.62%
Generation 3
tolerance = 72191.64935
acceptance rate = 18.74%
Generation 4
tolerance = 21204.77097
acceptance rate = 11.53%
Generation 5
tolerance = 7452.74757
acceptance rate = 8.10%
Generation 6
tolerance = 3250.22571
acceptance rate = 7.74%
If we want to run the method for a few more generations, there is no need to start from the beginning.
Instead, we can use continue_posterior_sample() along with the next_tol attribute to set the tolerance.
Let’s perform 2 additional iterations:
abcSEIR.continue_posterior_sample(N=250, tol=abcSEIR.next_tol, G=2, q=0.25, progress=True)
Generation 1
tolerance = 2232.01873
acceptance rate = 13.35%
Generation 2
tolerance = 1833.77615
acceptance rate = 21.76%
There are built in methods to plot the posterior distribution and the corresponding fit to the data:
abcSEIR.plot_posterior_histograms();
abcSEIR.plot_pointwise_predictions();
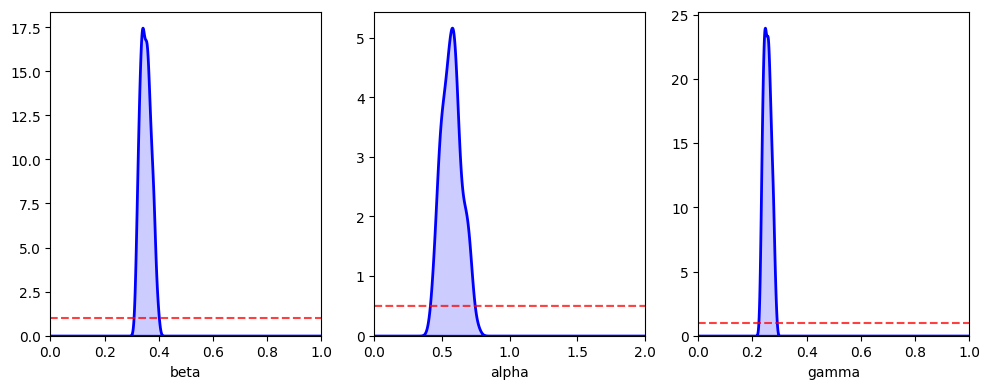
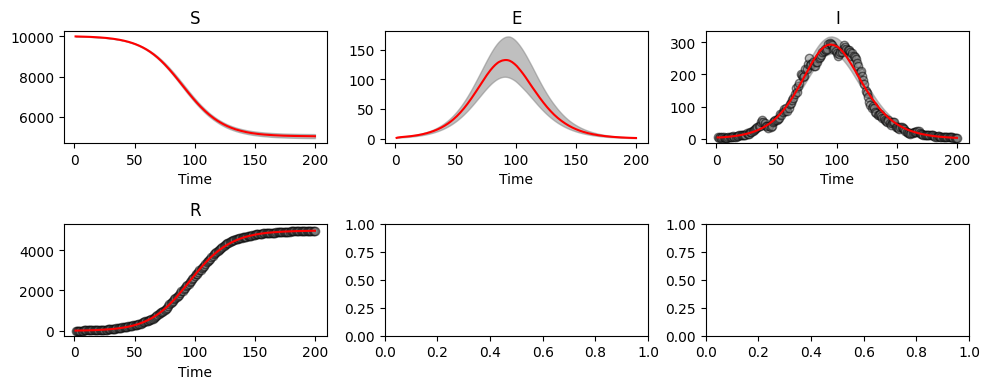
The posterior draws are contained within abcSIR.res.
This can be useful if output needs to be saved, or for calculation credible intervals.
We see here that the 95% credible intervals are consistent with the true parameter values.
print(f'beta={np.median(abcSEIR.res[:,0]):.3f} ({np.quantile(abcSEIR.res[:,0], 0.025):.3f}, {np.quantile(abcSEIR.res[:,0], 0.975):.3f})')
print(f'alpha={np.median(abcSEIR.res[:,1]):.3f} ({np.quantile(abcSEIR.res[:,1], 0.025):.3f}, {np.quantile(abcSEIR.res[:,1], 0.975):.3f})')
print(f'gamma={np.median(abcSEIR.res[:,2]):.3f} ({np.quantile(abcSEIR.res[:,2], 0.025):.3f}, {np.quantile(abcSEIR.res[:,2], 0.975):.3f})')
beta=0.350 (0.318, 0.388)
alpha=0.566 (0.437, 0.712)
gamma=0.254 (0.231, 0.281)
Fitting an SEIR model (with only Infected known)#
We now fit the same model, but assume we only have access to data concerning the infected component.
All that changes code-wise is that we omit the recovered time series when inputting the data and specify that we only have information for the infected population in the last argument of create_loss.
We do this and run the ABC algorithm for 8 generations.
objSEIR2 = abc.create_loss("PoissonLoss",
parameters,
ode_SEIR,
x0, t[0],
t[1:], sol_i_r[1:,0], # now we only pass one column of epi data
['I']) # now we only have information regarding the infected compartment
abcSEIR2 = abc.ABC(objSEIR2, parameters)
abcSEIR2.get_posterior_sample(N=250, tol=np.inf, G=8, q=0.25, progress=True)
abcSEIR2.plot_posterior_histograms();
abcSEIR2.plot_pointwise_predictions();
Generation 1
tolerance = inf
acceptance rate = 73.75%
Generation 2
tolerance = 57967.89694
acceptance rate = 23.21%
Generation 3
tolerance = 14573.65549
acceptance rate = 15.63%
Generation 4
tolerance = 4955.22257
acceptance rate = 7.07%
Generation 5
tolerance = 1747.46397
acceptance rate = 4.04%
Generation 6
tolerance = 1008.39222
acceptance rate = 4.40%
Generation 7
tolerance = 795.51825
acceptance rate = 4.46%
Generation 8
tolerance = 750.03026
acceptance rate = 7.85%
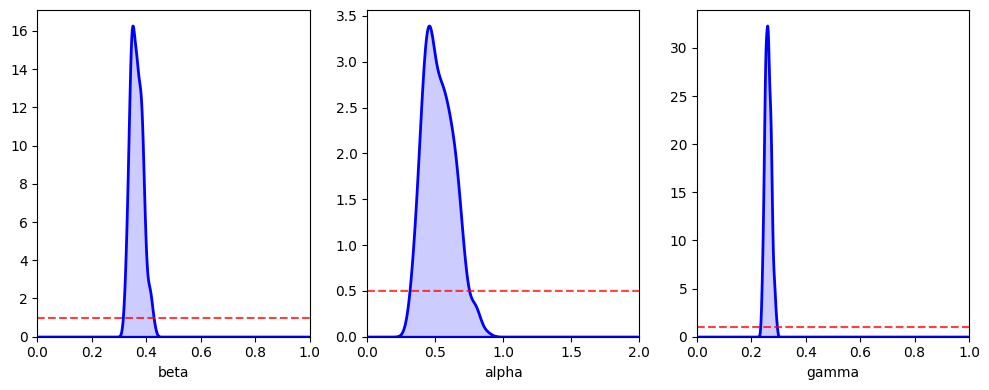
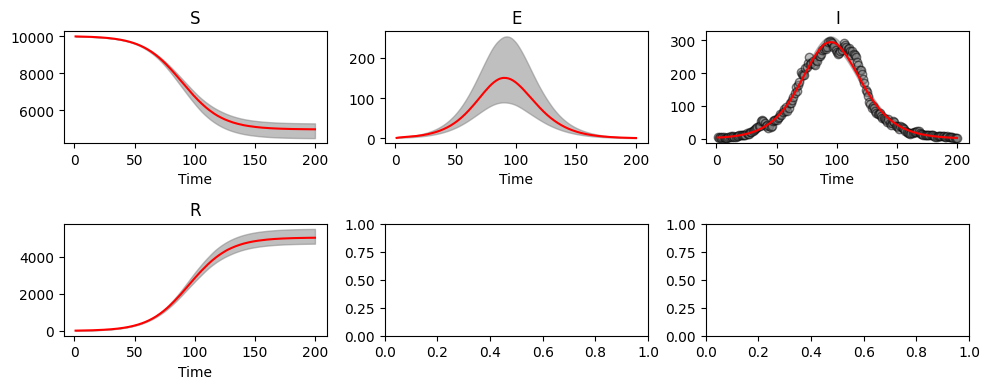
print(f'beta={np.median(abcSEIR2.res[:,0]):.3f} ({np.quantile(abcSEIR2.res[:,0], 0.025):.3f}, {np.quantile(abcSEIR2.res[:,0], 0.975):.3f})')
print(f'alpha={np.median(abcSEIR2.res[:,1]):.3f} ({np.quantile(abcSEIR2.res[:,1], 0.025):.3f}, {np.quantile(abcSEIR2.res[:,1], 0.975):.3f})')
print(f'gamma={np.median(abcSEIR2.res[:,2]):.3f} ({np.quantile(abcSEIR2.res[:,2], 0.025):.3f}, {np.quantile(abcSEIR2.res[:,2], 0.975):.3f})')
beta=0.362 (0.326, 0.413)
alpha=0.516 (0.345, 0.785)
gamma=0.260 (0.240, 0.284)
We still see estimates in agreement with the true parameter values, even though we have reduced the amount of data made available to the ABC algorithm.
Fitting an SIR model (with only Infected known)#
Of course, we may not know the underlying mechanisms and might instead attempt to fit an SIR model to the infected data. We follow similar steps as before, but now specifying an SIR model:
parameters = [abc.Parameter('beta', 'unif', 0, 1, logscale=False),
abc.Parameter('gamma', 'unif', 0, 1, logscale=False)]
# Params
paramEval=[('beta', 0), ('gamma', 0), ('N', n_pop)]
# Initial conditions now doen't require E0
x0=[n_pop-i0, i0, 0]
# Set up pygom object
ode_SIR = common_models.SIR(param=paramEval)
objSIR = abc.create_loss("PoissonLoss", parameters, ode_SIR, x0, t[0], t[1:], sol_i_r[1:,0], ['I'])
abcSIR = abc.ABC(objSIR, parameters)
abcSIR.get_posterior_sample(N=250, tol=np.inf, G=8, q=0.25, progress=True)
abcSIR.plot_posterior_histograms();
abcSIR.plot_pointwise_predictions();
Generation 1
tolerance = inf
acceptance rate = 50.40%
Generation 2
tolerance = 97090.54633
acceptance rate = 28.57%
Generation 3
tolerance = 26871.99949
acceptance rate = 27.06%
Generation 4
tolerance = 7946.79001
acceptance rate = 30.05%
Generation 5
tolerance = 2164.64690
acceptance rate = 30.86%
Generation 6
tolerance = 1108.75380
acceptance rate = 33.83%
Generation 7
tolerance = 936.24091
acceptance rate = 32.51%
Generation 8
tolerance = 900.98276
acceptance rate = 31.69%
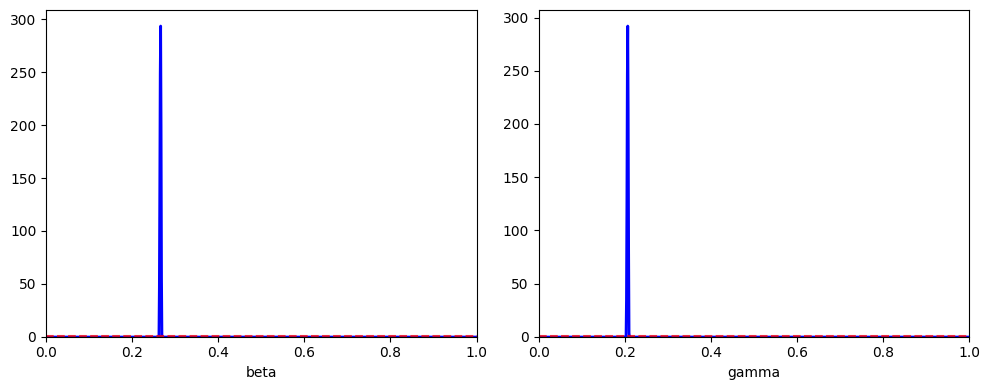
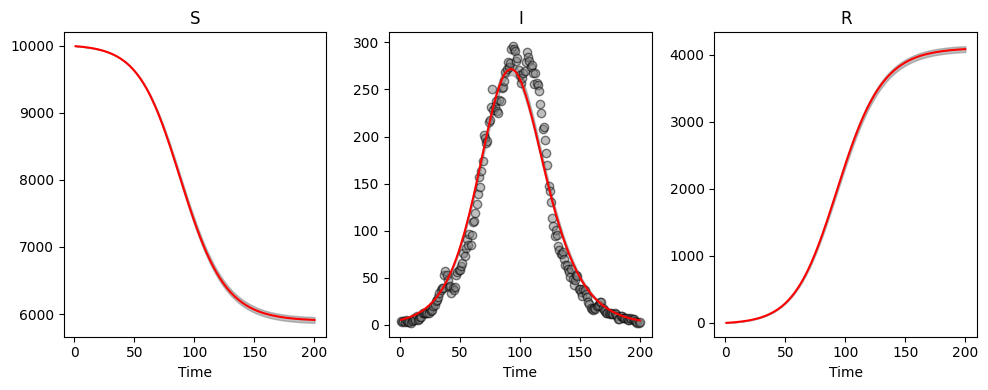
Although we see smaller credible intervals, this actually reflects the restriction in model fitting, rather than increased precision. We see that our inappropriate model choice here results in poorer parameter estimates:
print(f'beta={np.median(abcSEIR.res[:,0]):.3f} ({np.quantile(abcSEIR.res[:,0], 0.025):.3f}, {np.quantile(abcSEIR.res[:,0], 0.975):.3f})')
print(f'gamma={np.median(abcSEIR.res[:,1]):.3f} ({np.quantile(abcSEIR.res[:,1], 0.025):.3f}, {np.quantile(abcSEIR.res[:,1], 0.975):.3f})')
beta=0.350 (0.318, 0.388)
gamma=0.566 (0.437, 0.712)
Initial conditions#
In addition to inferring model parameters, the ABC methods can be used to estimate initial conditions, after all, it is unlikely that \(I(t=0)\) is known with certainty.
To do this, the state that we wish to estimate the initial condition for should be included in the parameters:
parameters = [abc.Parameter('beta', 'unif', 0, 1, logscale=False),
abc.Parameter('alpha', 'unif', 0, 2, logscale=False),
abc.Parameter('gamma', 'unif', 0, 1, logscale=False),
abc.Parameter('I', 'unif', 0, 20, logscale=False)]
The remaining code is the same as before. Again, we still need to pass variables even if they are unknown - in this case the initial number of infected individuals.
i0=5
x0=[n_pop-i0, 0, i0, 0]
objSEIR3 = abc.create_loss("PoissonLoss",
parameters,
ode_SEIR,
x0, t[0],
t[1:], sol_i_r[1:,0], # now we only pass one column of epi data
['I']) # now we only have information regarding the infected compartment
abcSEIR3 = abc.ABC(objSEIR3, parameters)
We run the algorithm for 8 generations:
abcSEIR3.get_posterior_sample(N=250, tol=np.inf, G=8, q=0.25, progress=True)
abcSEIR3.plot_posterior_histograms();
abcSEIR3.plot_pointwise_predictions();
Generation 1
tolerance = inf
acceptance rate = 72.89%
Generation 2
tolerance = 58067.08238
acceptance rate = 15.76%
Generation 3
tolerance = 15858.17892
acceptance rate = 13.94%
Generation 4
tolerance = 5420.38644
acceptance rate = 7.54%
Generation 5
tolerance = 2185.32098
acceptance rate = 5.41%
Generation 6
tolerance = 1182.18264
acceptance rate = 2.42%
Generation 7
tolerance = 878.11360
acceptance rate = 1.57%
Generation 8
tolerance = 777.43372
acceptance rate = 0.64%
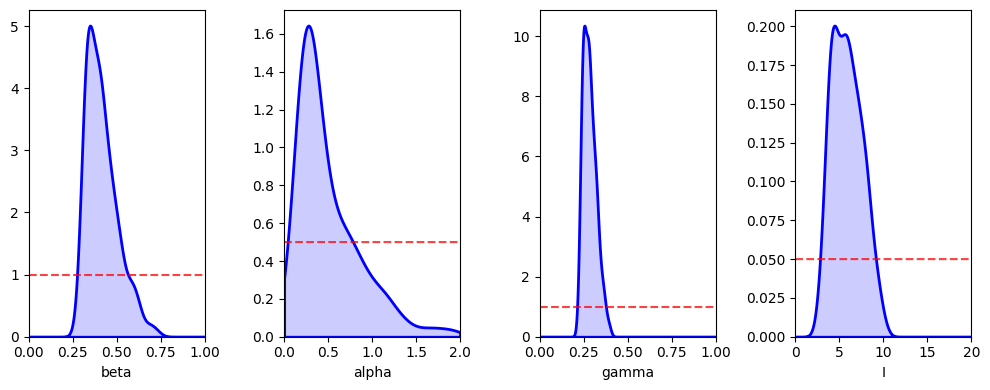
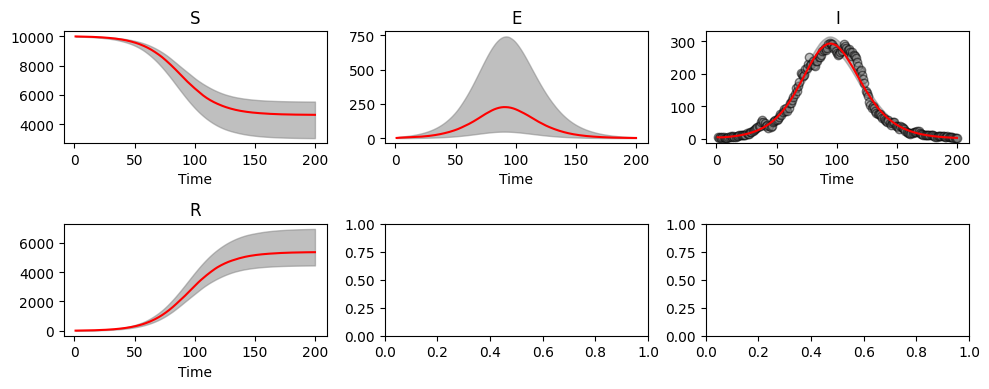
print(f'beta={np.median(abcSEIR3.res[:,0]):.3f} ({np.quantile(abcSEIR3.res[:,0], 0.025):.3f}, {np.quantile(abcSEIR3.res[:,0], 0.975):.3f})')
print(f'alpha={np.median(abcSEIR3.res[:,1]):.3f} ({np.quantile(abcSEIR3.res[:,1], 0.025):.3f}, {np.quantile(abcSEIR3.res[:,1], 0.975):.3f})')
print(f'gamma={np.median(abcSEIR3.res[:,2]):.3f} ({np.quantile(abcSEIR3.res[:,2], 0.025):.3f}, {np.quantile(abcSEIR3.res[:,2], 0.975):.3f})')
print(f'I0={np.median(abcSEIR3.res[:,3]):.3f} ({np.quantile(abcSEIR3.res[:,3], 0.025):.3f}, {np.quantile(abcSEIR3.res[:,3], 0.975):.3f})')
beta=0.400 (0.307, 0.623)
alpha=0.366 (0.141, 1.408)
gamma=0.278 (0.230, 0.368)
I0=5.701 (3.106, 9.250)
Whilst credible intervals are consistent with our parameters, they are wider than before. This is because with increased numbers of parameters there are more ways for our model to fit the data.